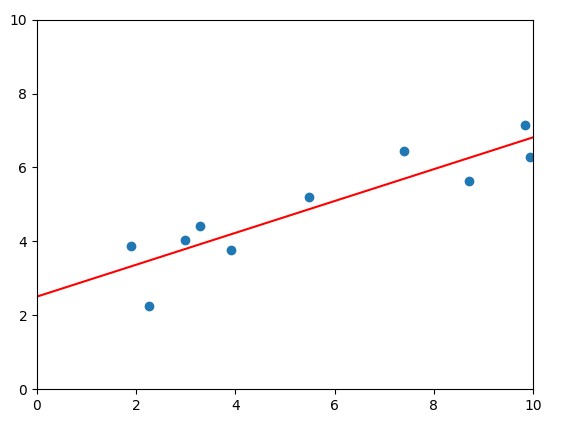
좋은 직선이란? 실제값(y)과 예측값(\(\beta_0X + \beta_1\) )의 차이가 적을수록 좋다.
실제값: input에 대한 실제 output 예측값: input에 대한 예측값, 직선에 x를 넣었을 때 나오는 값
Loss Function (손실함수) \[\sum_{i}^n (y_i - (\beta_0 + \beta_1x_i))^2\]
= Cost Funtion
loss = 예측값과 실제값의 차이
기계학습을 통해 결국 최소로 만들고자 하는 것,학습은 loss를 줄이는 방향으로 진행된다.
차이를 제곱해서 더하는 이유: 차이가 음수, 양수 모두 존재한다면 전체 차이를 구하기 위해 모두 더할 때 음수, 양수 차이가 상쇄 되어 버린다. -> 실제로는 차이가 많이 나도 전체 차이는 0이 나올 수도 있다
좋은 직선, beta 값을 찾는 법
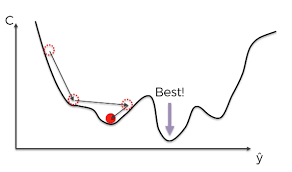
Gradient Descent (경사하강법)
loss function을 최소로 만드는 \(\beta_0 \beta_1\) 찾기
현재 위치에서 기울기가 가장 낮은 쪽으로 이동
현재 위치에서 기울기(미분값, 경사)를 구하고 경사의 반대 방향으로 이동시키면 극값이 나온다.
경사의 반대 방향 의미: 어떤 점에서 기울기가 양수라면 우상향 그래프, 최솟값으로 가기 위해서는 왼쪽(음수 방향)으로 이동해야 하고, 기울기가 음수라면 우하향 그래프이므로 최솟값으로 오른쪽(양수 방향)으로 이동해야 한다.
다음 점 위치:
지역 최적해로 수렴, 전역 최적해 보장 X
출처: 리브레 위키
Scikit-learn을 이용한 회귀분석
importmatplotlib.pyplotaspltimportnumpyasnpfromsklearn.linear_modelimportLinearRegression# loss function 구현
defloss(x,y,beta_0,beta_1):N=len(x)l=0# loss 값
foriinrange(N):l+=(y[i]-(beta_0+beta_1*x[i]))**2returnl# sample data
X=[8.70153760,3.90825773,1.89362433,3.28730045,7.39333004,2.98984649,2.25757240,9.84450732,9.94589513,5.48321616]Y=[5.64413093,3.75876583,3.87233310,4.40990425,6.43845020,4.02827829,2.26105955,7.15768995,6.29097441,5.19692852]train_X=np.array(X).reshape(-1,1)# 10x1로 reshape
train_Y=np.array(Y).reshape(-1,1)###########
### 모델 객체 생성 및 train
lrmodel=LinearRegression()lrmodel.fit(train_X,train_Y)beta_0=lrmodel.intercept_# lrmodel로 구한 직선의 y절편
beta_1=lrmodel.coef_[0]# lrmodel로 구한 직선의 기울기
###########
### 학습 결과 출력
print("beta_0: %f"%beta_0)print("beta_1: %f"%beta_1)print("Loss: %f"%loss(X,Y,beta_0,beta_1))plt.scatter(X,Y)plt.plot([0,10],[beta_0,10*beta_1+beta_0],c='r')plt.xlim(0,10)# 그래프의 X축을 설정합니다.
plt.ylim(0,10)# 그래프의 Y축을 설정합니다.
s="lee 010-2222-3333 kim 010-5959-5958 park 01011112222"p="(010)\-\d{4}\-(\d{4})"print(re.sub(p,"\g<1>-****-\g<2>",s))'''
lee vaild!
kim vaild!
park 01011112222
'''
ex. 전화번호 가운데 네 자리 블라인드(**) 하기
s="lee 010-2222-3333 kim 010-5959-5958 park 01011112222"p="(010)\-\d{4}\-(\d{4})"print(re.sub(p,"\g<1>-****-\g<2>",s))'''
lee 010-****-3333
kim 010-****-5958
park 01011112222
'''
틱택토 게임을 구현해봤다. 파이썬은 C/C++에 비해서 문자열 비교가 너무 쉬워서 너무 행복하다.
### 22.10.06
### 틱택토 게임 구현
### class 변환해서 구현
importtimeclassTicTacToe:def__init__(self):self.board={(i+1):" "foriinrange(9)}self.turn=0self.player="B"self.markers={"A":"X","B":"O"}defprint_board(self):print("")foriinrange(1,10):print(f"{i}: {self.board[i]} ",end=" ")ifi%3==0:print("")#####################
### player 전환
defnext_player(self):ifself.turn%2==0:# A 차례
return"A"else:return"B"######################
### input 관리
definsert_input(self,player,marker):input_slot=int(input(f"{player} >> marker({marker}) 표시 위치를 선택하세요(1~9): "))whileinput_slot<1orinput_slot>9orself.board[input_slot]!=" ":input_slot=int(input(f"{player} >> 적절한 범위와 빈 슬롯의 번호를 다시 입력하세요(1~9): "))self.board[input_slot]=markerself.turn+=1################
### 승패 결정: 승부가 끝났다면 True 반환
defwin_game(self):# 세로
forstartinrange(1,4):ifself.board[start]!=" "andself.board[start]==self.board[start+3]==self.board[start+6]:returnTrue# 가로
forstartinrange(1,9,3):ifself.board[start]!=" "andself.board[start]==self.board[start+1]==self.board[start+2]:returnTrue# 대각선
ifself.board[5]!=" "and \
(self.board[1]==self.board[5]==self.board[9]orself.board[3]==self.board[5]==self.board[7]):returnTrue################
### 게임을 더 할 건지
defplay_again(self):c=input(f"New game? (y/n): ")ifc=="y":self.__init__()returnTrueelse:returnFalse################
### 메인 게임 실행 함수
defgame(self):cont=True# continue game?
whilecont:self.print_board()self.player=self.next_player()# self.count 기준으로 다음 순서 정하기
### marker 위치 input 받기
self.insert_input(self.player,self.markers[self.player])### 승패 판정
res=self.win_game()### 게임 끝, 다음 게임 진행 여부
ifres:self.print_board()time.sleep(0.5)print(f"{self.player} WIN -------------------\n")cont=self.play_again()# 새로운 게임
ifnotresandself.turn==9:# 무승부 판정
time.sleep(0.5)print(f"TIE GAME -----------\n")cont=self.play_again()# 새로운 게임
ttt=TicTacToe()ttt.game()
# 넷 다 같은 집합
set1={1,3,5}set2=set([1,3,5])# set() 함수를 사용해 list to set 변환
set3=set([5,3,1])set3={3,1,3,5}# 집합은 중복 원소 표시하지 않음
집합 원소 추가/삭제
myset={1,2,3,4}# 원소 추가
myset.add(5)# 여러 개의 원소 한 번에 추가
myset.update([6,7,8])# 원소 제거
myset.remove(5)# 존재하지 않는 원소를 삭제하려고 한다면 에러
# 원소 제거
myset.discard(10)# 존재하지 않는 원소라면 아무것도 하지 않음
Return a callable object that fetches item from its operand using the operand’s getitem() method.
말이 어렵게 써있지만,
list, tuple, dictionary 등의 데이터에서 특정 항목을 가져온다.
sorted(), map()에서 활용 가능하도록 호출 가능한 형태를 반환
예시: sorted
학생들의 시험점수를 나타낸 리스트가 있고,
exam=[("Alice",80),("Jane",95),("Peter",72)]
시험 점수가 높은 학생 순으로 정렬하고 싶다면, sorted()에 들어갈 key 함수에 점수 기준으로 정렬하도록 설정해야 한다.
# 1. 리스트의 각 원소(학생)의 시험점수를 반환하는 함수를 만들고
defget_score(student):# (이름, 점수) 형식의 튜플
returnstudent[1]# 2. def_score 함수를 key로 넘겨주어 exam 데이터 속의 점수를 기준으로 정렬할 수 있도록 한다.
sorted_students=sorted(exam,key=get_score,reverse=True)
이때 itemgetter()를 사용한다면 get_socre 함수를 만들지 않고, 특정 원소를 바로 반환받을 수 있다.
# itemgetter(1): 1번째 원소를 반환
sorted_students=sorted(exam,key=itemgetter(1),reverse=True)
작동 원리
itemgetter(1)("ABCDEFG")### >>> 'B'
itemgetter(0,2)("ABCDEFG")# 여러 개의 값이 선택되면 tuple 형태로 반환
### >>> ('A', 'C')
# 요일의 맨 첫 글자만 따서 새로운 리스트를 만드려고 할 때
days=["MON","TUE","WED","THU","FRI","SAT","SUN"]new_days=[]fordayindays:new_days.append(day[0])print(new_days)# >>> ['M', 'T', 'W', 'T', 'F', 'S', 'S']
위와 같이 for문으로 순회하면서 만들어내야 하는 리스트를 한 줄로 짧게 만들 수 있게 하는 문법이 리스트 컴프리헨션이다.
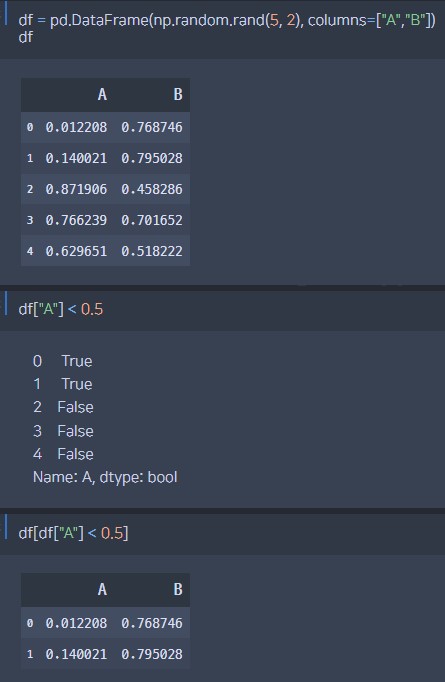
df=pd.DataFrame(np.random.rand(5,2),columns=["A","B"])df.query("A<0.5")df.query("A<0.5 and B>0.3")# 조건 여러 개: query 문자열 안에 and or 사용
3. 문자열 검색
# 1. # Cat을 포함한 문자열 찾기
df["Animal"].str.contains("Cat")# 2. # Cat과 완전히 매칭되는 문자열 찾기
df.Animal.str.match("Cat")# 특징: match() 안에 정규표현식 사용 가능
# 3. 2와 같음
df["Animal"]=="Cat"
데이터: 함수 처리
dataframe의 데이터에 함수 적용하기
df=pd.DataFrame(np.arange(5),columns="Num")defsquare(x):# 제곱하는 함수
returnx**2# Num 열의 데이터들을 제곱하여 새로운 열 Square을 추가해보자
# 1. 만들어둔 square 함수 사용
df["Square"]=df["Num"].apply(square)# 2. 람다식 사용
df["Square"]=df["Num"].apply(lambdax:x**2)
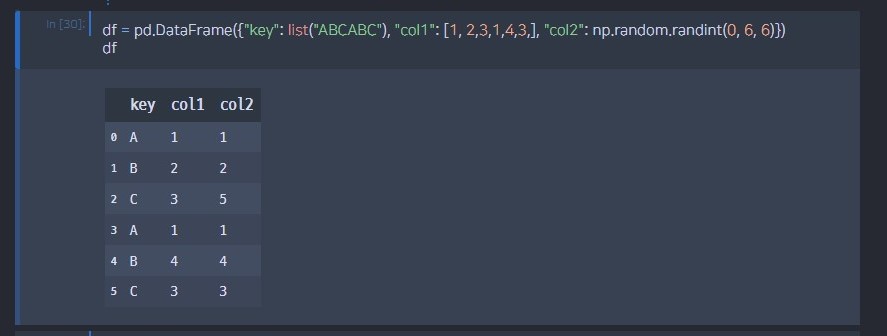
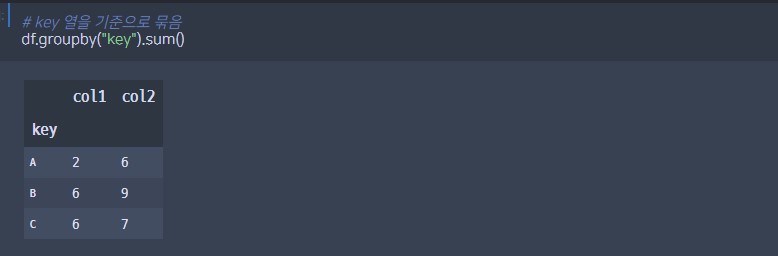
# key 열을 기준으로 묶음 -> 합계
df.groupby("key").sum()# 두 개의 열을 기준으로 묶음 -> 평균
df.groupby(["key","col1"]).mean()
결과
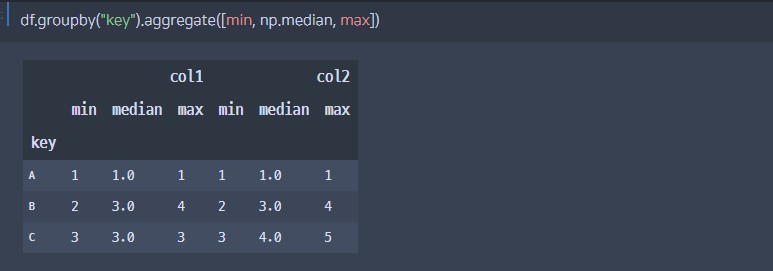
2. aggregate()
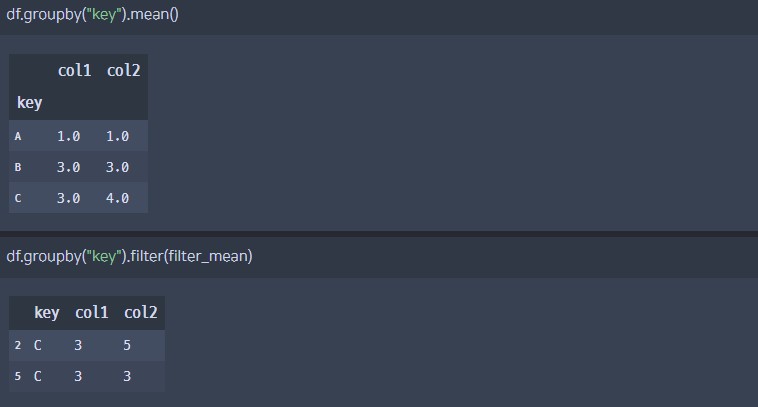
groupby를 통해 집계를 한 번에 계산하는 함수
df.groupby(''' /기준열/ ''').aggregate(''' /list or dict/ ''')# 1. 리스트 형태로 각 열에 공통적으로 적용
df.groupby("key").aggregate([min,np.median,max])# 2. 딕셔너리 형태로 각 열마다 다른 집계 수행
df.groupby("key").aggregate({"data1":min,"data2":sum})
# 일차별로, (row)
# 사람들의 평균 나이를 구함 (value)
# 성별로 라벨링 (col)
tb=df.pivot_table(index="일차",columns="성별",values="나이",aggfunc=np.mean# value 값을 어떻게 처리할건지
)print(tb)