Basic | K-fold Validation
in Machine Learning / Basic
과적합 방지를 위한 k-fold validation, scikit-learn을 이용한 구현
K-fold Validation
교차 검증 방법 중 하나
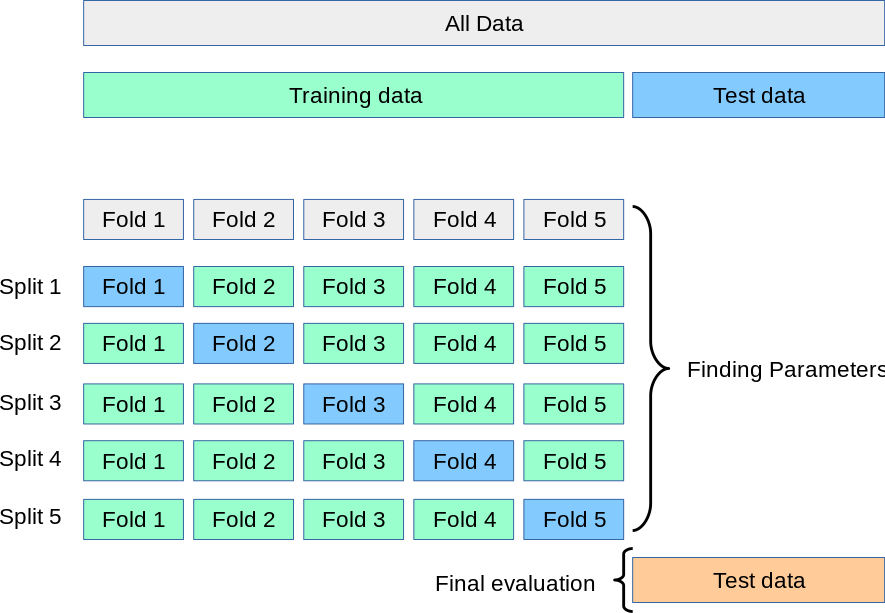
출처: Scikit-learn
k-fold validation 방식
- 훈련 데이터를 계속 변경하여 학습시킴 (특정 데이터에 지나치게 과적합 되는 것을 방지)
- 데이터 셋을 K개로 나눔
- K중 한 개를 검증용, 나머지를 훈련용으로 사용
- K개 모델의 평균 성능이 최종 모델 성능
- test data는 무조건 고정, 학습에 사용하지 않음
Scikit-learn의 KFold 사용법
>>> import numpy as np
>>> from sklearn.model_selection import KFold
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
>>> y = np.array([1, 2, 3, 4])
>>> kf = KFold(n_splits=2)
>>> kf.get_n_splits(X)
2
>>> print(kf)
KFold(n_splits=2, random_state=None, shuffle=False)
>>> for train_index, test_index in kf.split(X): # split을 이용해 반환된 인덱스 가져오기
... print("TRAIN:", train_index, "TEST:", test_index)
... X_train, X_test = X[train_index], X[test_index]
... y_train, y_test = y[train_index], y[test_index]
TRAIN: [2 3] TEST: [0 1]
TRAIN: [0 1] TEST: [2 3]
Scikit-learn을 이용한 k-fold 구현
fetch_california_housing 데이터를 이용해서 다중 회귀 분석을 구현해보고 모델의 점수를 매겨보자.
fetch_california_housing: scikit learn 라이브러리에서 지원하는 데이터셋 중 하나, California housing price 데이터- 먼저 train-test data를 split 한 후
- train data에 대해 scikit-learn의 KFold 모듈을 이용해 train-val로 다시 분리
- n_splits = 5
파이썬 구현 코드
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import LinearRegression
# sklearn의 KFold 모듈 불러오기
from sklearn.model_selection import KFold
def load_data():
X, y = fetch_california_housing(return_X_y=True)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.2, random_state=100)
return train_X, test_X, train_y, test_y
def kfold_regression(train_X, train_y):
# 반복문 내에서 횟수를 표시하기 위한 변수 설정하기
n_iter = 0
# 각 fold 마다 모델 검증 점수를 저장하기 위한 빈 리스트 생성하기
model_scores = []
# K-fold에서 몇 개로 분리할지
n_splits = 5
kfold = KFold(n_splits) # 5개로 분리
for train_idx, val_idx in kfold.split(train_X):
X_train, X_val = train_X[train_idx], train_X[val_idx]
y_train, y_val = train_y[train_idx], train_y[val_idx]
# 동일한 가중치 사용을 위해 각 fold 마다 모델 초기화 하기
model = LinearRegression()
# 모델 학습
model.fit(X_train, y_train)
# 각 Iter 별 모델 평가 점수 측정
score = model.score(X_val, y_val)
# 학습용 데이터의 크기를 저장합니다.
train_size = X_train.shape[0]
val_size = X_val.shape[0]
print("Iter : {0} Cross-Validation Accuracy : {1}, Train Data 크기 : {2}, Validation Data 크기 : {3}"
.format(n_iter, score, train_size, val_size))
n_iter += 1
# 전체 모델 점수를 저장하는 리스트에 추가하기
model_scores.append(score)
return kfold, model, model_scores
def main():
# 학습용 데이터와 테스트 데이터 불러오기
train_X, test_X, train_y, test_y = load_data()
# KFold 교차 검증을 통한 학습 결과와 회귀 모델을 반환하는 함수 호출하기
kfold, model, model_scores = kfold_regression(train_X, train_y)
# 전체 성능 점수의 평균 점수 출력
print("\n> 평균 검증 모델 점수 : ", np.mean(model_scores))
if __name__ == "__main__":
main()
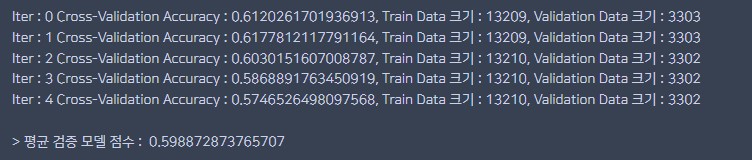
실행 결과
Reference
- https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.KFold.html