Pandas | Pandas 심화 (데이터 검색, 조건)
pandas 자주 쓰는 함수 정복하기: query(), apply(), groupby()
목차
- 데이터 조건 검색하기(query, str.contains)
- 데이터에 함수 적용하기(apply, lambda)
- 데이터 조건으로 묶기(groupby, aggregate)
- 멀티인덱스
- Pivot Table
import pandas as pd
데이터: 조건 검색
1. masking 연산
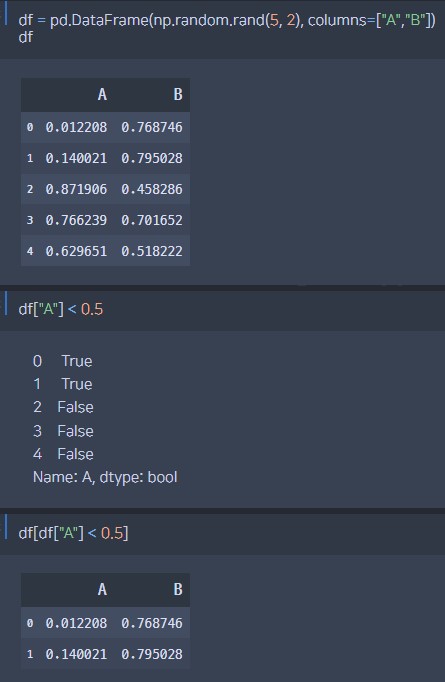
numpy와 마찬가지로 마스킹 연산 (True, False 반환)으로 원하는 row만 뽑을 수 있다.
df = pd.DataFrame(np.random.rand(5, 2), columns=["A","B"])
print(df[df["A"] < 0.5])
print(df[(df["A"] < 0.5) & (df["B"] > 0.3)] # 조건 여러개
making 연산 실행 예시
2. query() 함수 사용
df = pd.DataFrame(np.random.rand(5, 2), columns=["A","B"])
df.query("A<0.5")
df.query("A<0.5 and B>0.3") # 조건 여러 개: query 문자열 안에 and or 사용
3. 문자열 검색
# 1. # Cat을 포함한 문자열 찾기
df["Animal"].str.contains("Cat")
# 2. # Cat과 완전히 매칭되는 문자열 찾기
df.Animal.str.match("Cat") # 특징: match() 안에 정규표현식 사용 가능
# 3. 2와 같음
df["Animal"] == "Cat"
데이터: 함수 처리
dataframe의 데이터에 함수 적용하기
df = pd.DataFrame(np.arange(5), columns="Num")
def square(x): # 제곱하는 함수
return x**2
# Num 열의 데이터들을 제곱하여 새로운 열 Square을 추가해보자
# 1. 만들어둔 square 함수 사용
df["Square"] = df["Num"].apply(square)
# 2. 람다식 사용
df["Square"] = df["Num"].apply(lambda x:x**2)
데이터: 그룹으로 묶기 (조건부 집계)
1. groupby()
특정 열을 기준으로 데이터를 집계
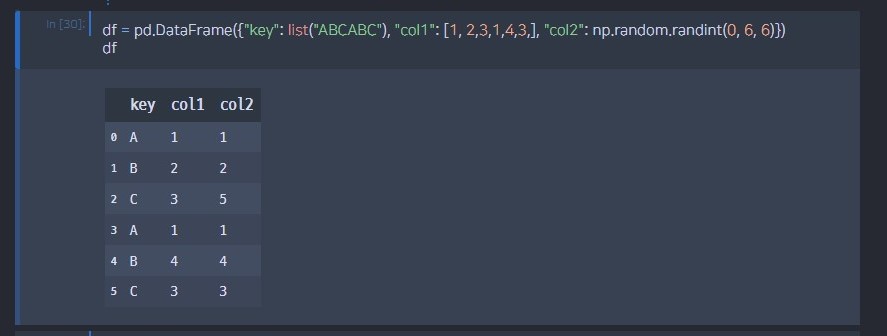
df = pd.DataFrame({"key": list("ABCABC"), "col1": [1, 2,3,1,4,3,], "col2": np.random.randint(0, 6, 6)})
df 출력
위와 같은 데이터가 있을 때 key값을 기준으로 묶어 합계를 내고 싶다면.
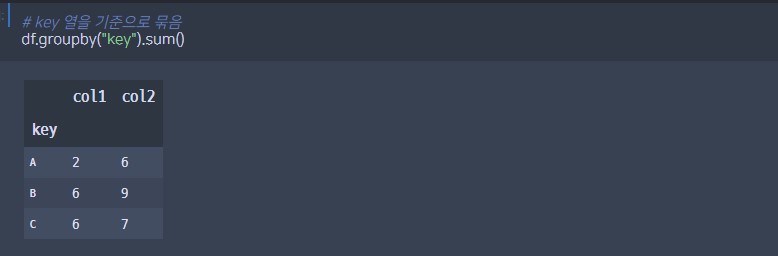
# key 열을 기준으로 묶음 -> 합계
df.groupby("key").sum()
# 두 개의 열을 기준으로 묶음 -> 평균
df.groupby(["key", "col1"]).mean()
결과
2. aggregate()
groupby를 통해 집계를 한 번에 계산하는 함수
df.groupby(''' /기준열/ ''').aggregate(''' /list or dict/ ''')
# 1. 리스트 형태로 각 열에 공통적으로 적용
df.groupby("key").aggregate([min, np.median, max])
# 2. 딕셔너리 형태로 각 열마다 다른 집계 수행
df.groupby("key").aggregate({"data1":min, "data2":sum})
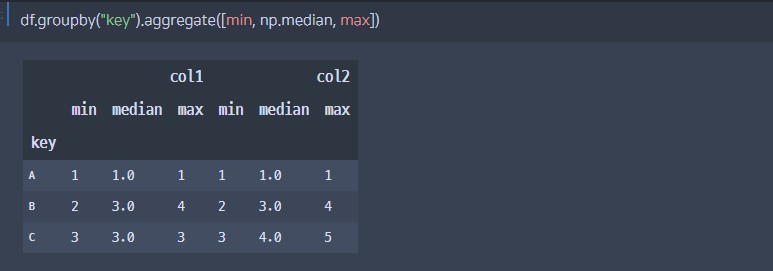
각 열의 min, median, max 값 한 번에 계산
3. filter()
groupby를 통해 그룹 속성을 기준으로 데이터 필터링
- groupby와 함께 사용하여 특정 기준을 만족하는 데이터 row만 출력
- column 별 계산
def filter_mean(x):
return x["col2"].mean() > 3
df.groupby("key").filter(filter_mean)
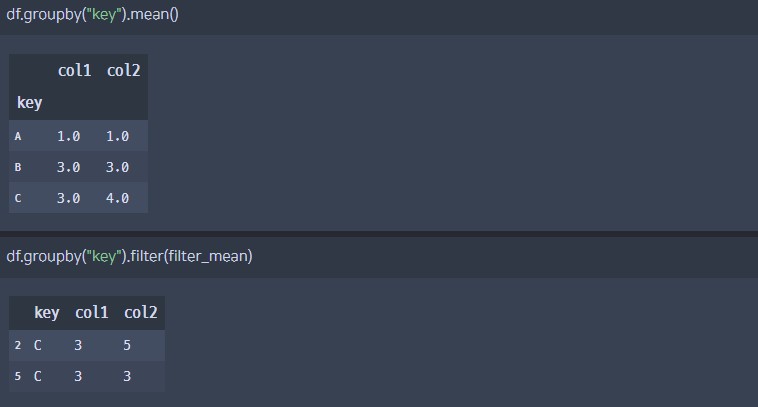
결과
col2의 mean이 3초과인 데이터 ()= key가 C인) row(2, 5)만 필터링
4. apply()
groupby를 통해서 묶은 데이터에 함수 적용
- apply를 groupby와 함께 사용할 수 있다.
- column 별 계산
멀티인덱스
인덱스가 중복될 때, 계층적으로 만들어진다.
- row, col 모두 계층적으로 생성
- iloc, loc 사용 가능
df = pd.DataFrame(np.random.randn(10, 4), index=[list("AABBBAAABB"), [1, 2, 1, 1, 2, 1, 2, 2, 1, 1, ]], columns=[["col1", "col1", "col2", "col2"], [1, 2, 3, 4]])
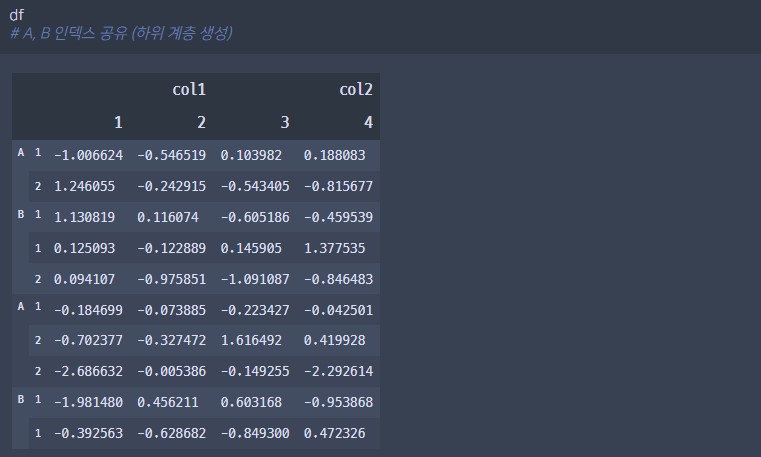
df 출력 결과
# 멀티인덱스 접근 예시
df["col1"][1]
Pivot Table
데이터에서 필요한 자료만 뽑아서 새롭게 요약
index: 행 인덱스로 들어갈 keycolumn: 열 인덱스로 라벨링될 값value: 분석할 데이터 (값)
# 일차별로, (row)
# 사람들의 평균 나이를 구함 (value)
# 성별로 라벨링 (col)
tb = df.pivot_table(
index="일차", columns="성별", values="나이",
aggfunc=np.mean # value 값을 어떻게 처리할건지
)
print(tb)

결과